I work on logging and analytics, and manage the underlying service that Supabase Logs and Logflare. The service does over 7 billion requests each day with traffic constantly growing, and these devlog posts talk a bit about my day-to-day open source dev work.
It serves as some insight into what one can expect when working on high availability software, with real code snippets and PRs too. Enjoy!😊
When working with distributed Erlang applications at Logflare/Supabase, we encountered an interesting issue where the :global_name_server would become overwhelmed with messages, leading to a boot loop situation. This issue is particularly relevant when dealing with the prevent_overlapping_partitions feature.
Understanding the Boot Loop
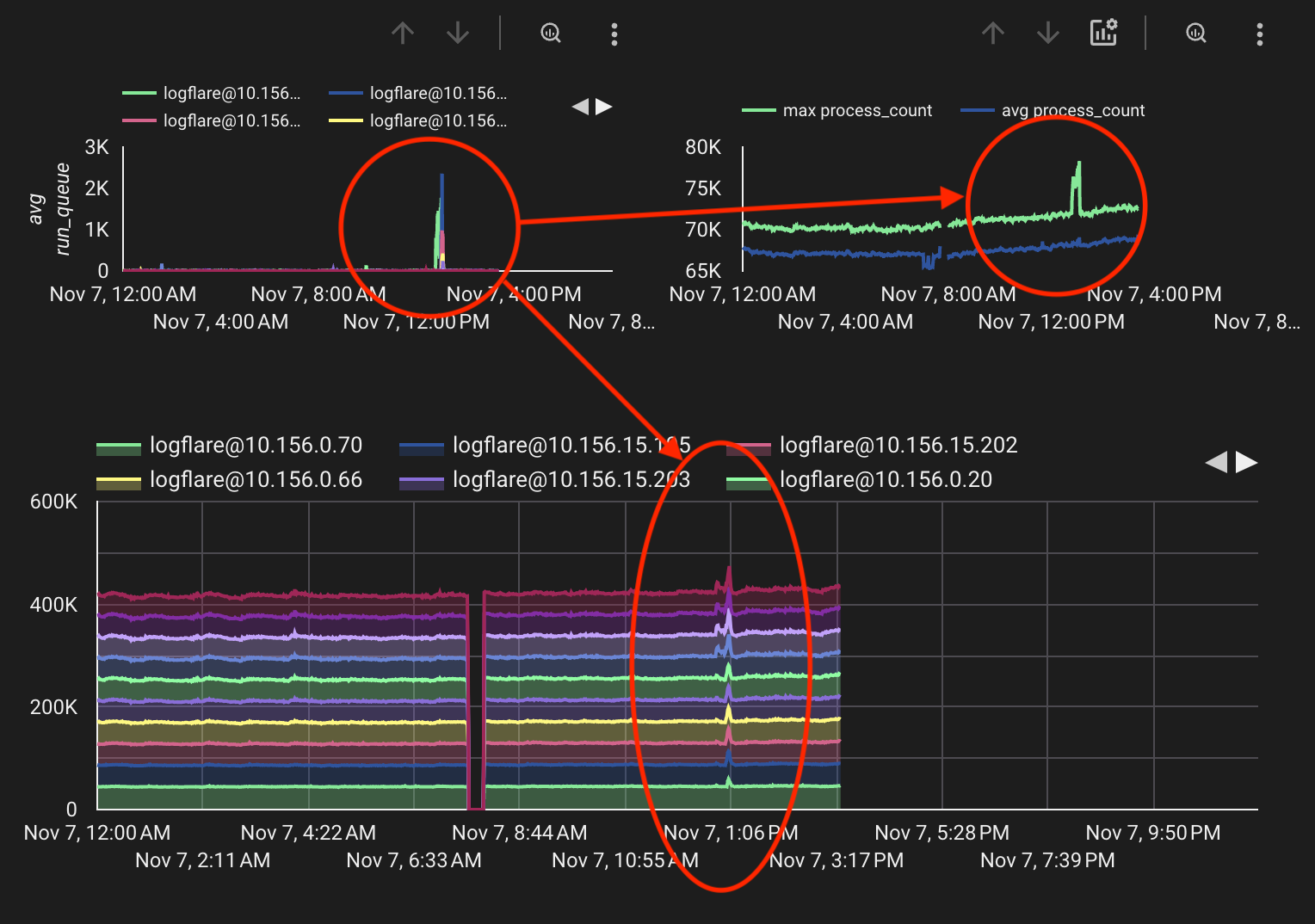
The boot loop behaviour comes about when the global name server becomes overwhelmed with messages in scenarios involving network partitions, where many nodes are connecting or disconnecting simultaneously. This can create a cascade effect where:
- The global name server receives too many messages
- Message processing delays lead to timeouts
- Node reconnection attempts trigger more messages
GOTO 1
This behaviour is closely related to OTP issue #9117, and within the issue, I highlighted several main potential factors that could be causing the issue depsite the throw fix that Rickard Green had implemented.
We also observed that this behaviour occurs even when not using :global at all. For Logflare, we had migrated our distributed name registration workloads to use the wonderful :syn library. Hence, this bug is more related to the core syncing protocol of :global.
The throw in restart_connect()
When the :global server attempts to connect to a new node, it will perform a lock to sync the registered names between each node. In the syncing protocol, the :global server will perform a check to verify that the node is not already attempting to perform a sync (indicated by the pending state) within the server. If it is already attempting a sync, it will instead cancel the connection attempt and retry the connection.
Without a throw, it will result in a deadlock situation, where the :global server will wait forever for the node to complete the sync.
prevent_overlapping_partitions to the rescue
As documented in :global:
As of OTP 25, global will by default prevent overlapping partitions due to network issues by actively disconnecting from nodes that reports that they have lost connections to other nodes. This will cause fully connected partitions to form instead of leaving the network in a state with overlapping partitions.
This means that :global by default will actively disconnect from nodes that report that they have lost connections to other nodes. For small clusters, this is generally a good feature to have so that the cluster can quickly recover from network issues. However, for large clusters, this can cause a lot of unnecessary disconnections and can lead to the above boot loop issue.
As of time of writing, disabling the prevent_overlapping_partitions feature has allowed our cluster to overcome this boot loop issue by preventing a flood of disconnection messages across clusters. However, this flag needs to be used with caution when using the :global server for name registration, as it may result in inconsistencies if there are overlapping partitions and mutliple instances of the same name are registered. Application code needs to be able to handle this case.
Monitoring strategies
When dealing with large clusters, I would recommend implementing monitoring for:
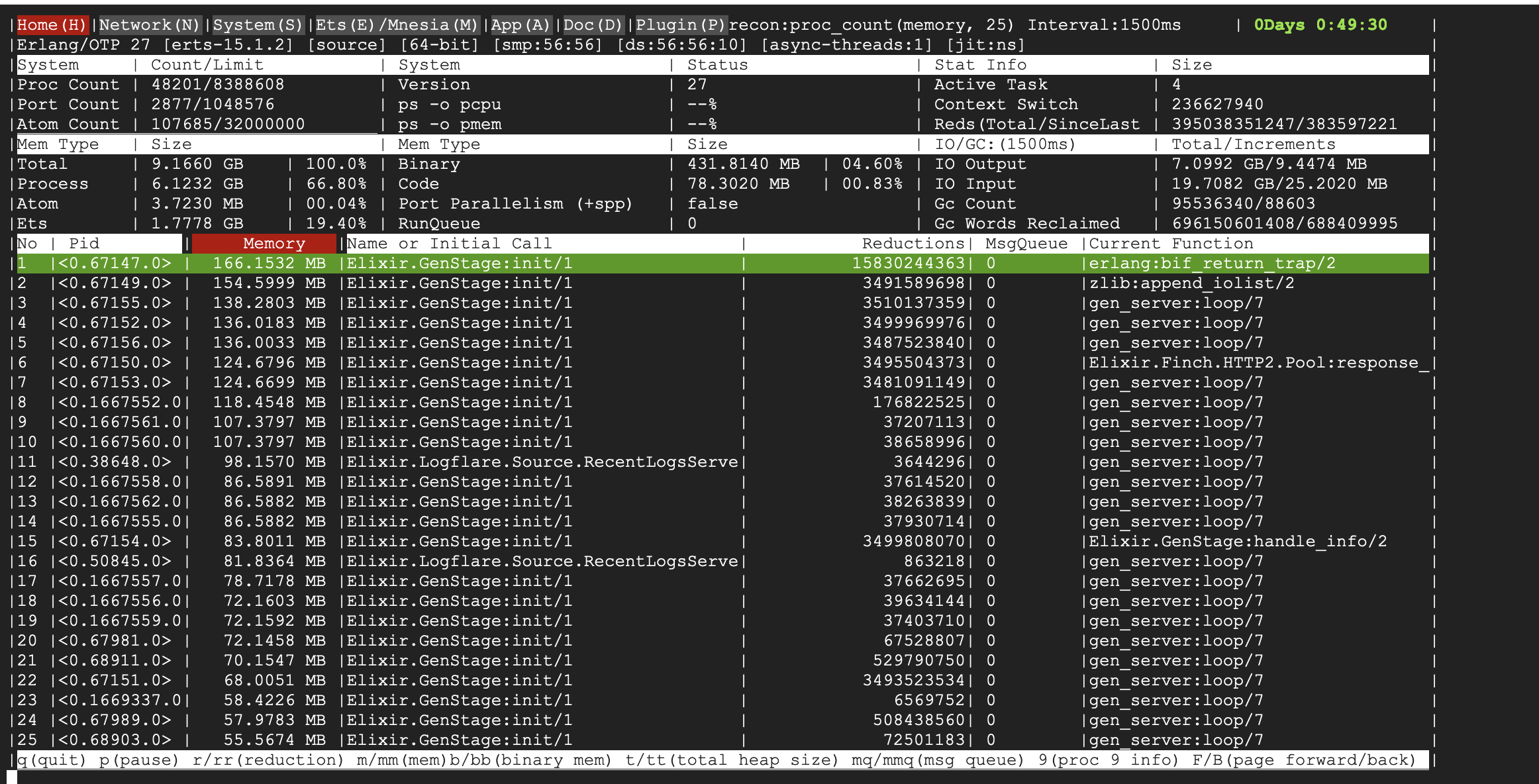
- global name server message queue length -- the main indicator of the issue
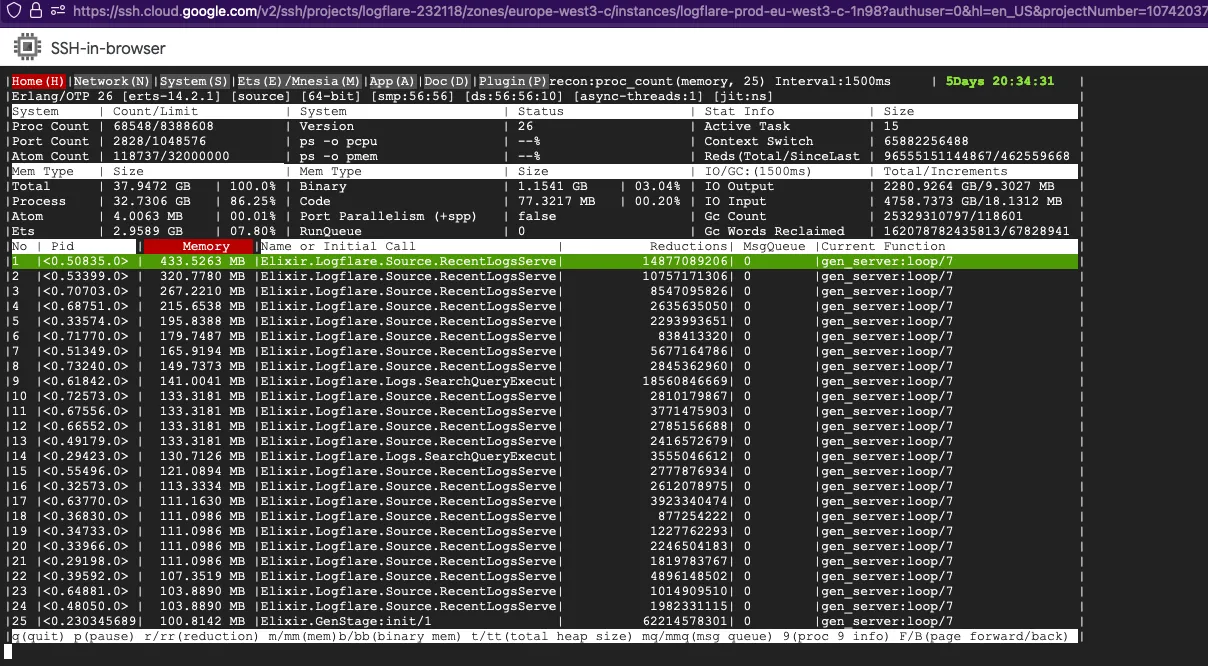
- memory usage of the global name server -- a secondary indicator of long message queues
Tracing the :global server callbacks at runtime is also a good way to debug the issue, though it is usually not easy as the time window before the node goes out-of-memory is usually very short.
I explain this in more detail in my post on understanding Erlang's :global prevent_overlapping_partitions Option.